Maskininlärning (Machine Learning, ML) representerar ett nytt paradigm i programmering, där du istället för att programmera explicita regler på ett språk som Java eller C ++, bygger ett system som tränas och lärs upp på data från ett stort antal exempel, för att sedan kunna dra slutsatser av ny data baserat på de mönster som identifierats utifrån träningsdatat.
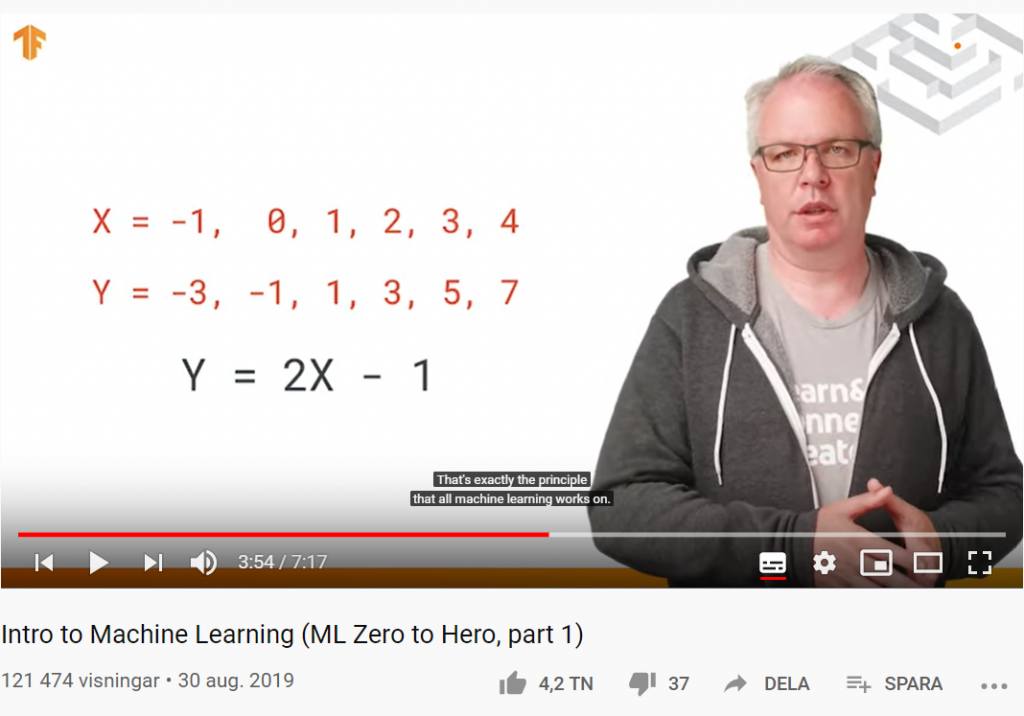
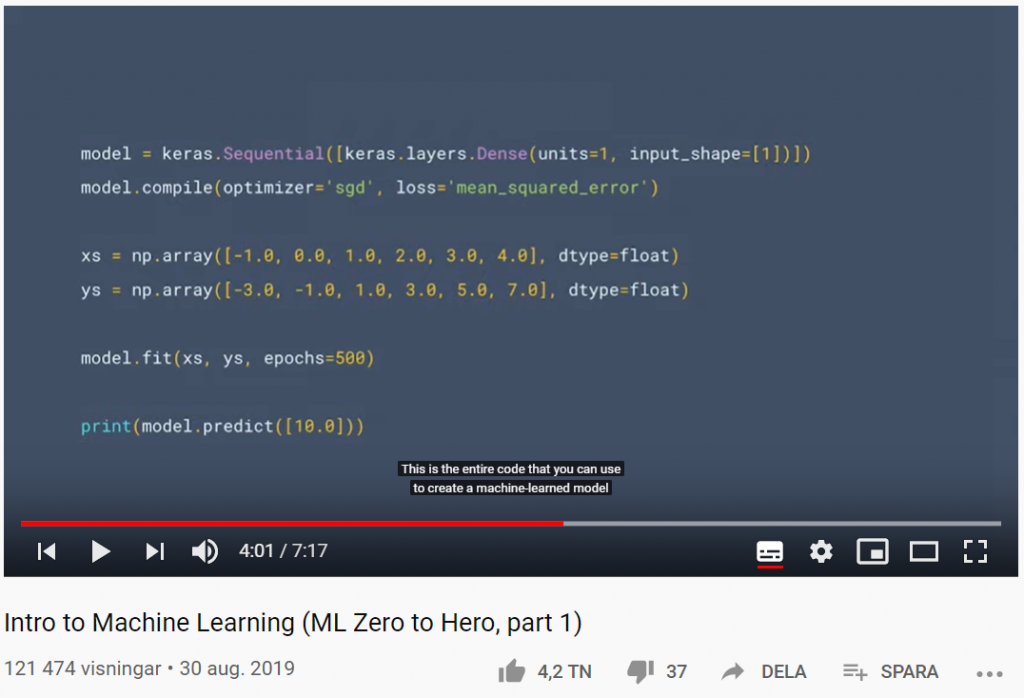
Men hur ser ML egentligen ut? I del ett av Machine Learning Zero to Hero går AI-evangelisten Laurence Moroney (lmoroney @) genom ett grundläggande Hello World-exempel på hur man bygger en ML-modell och introducerar idéer som vi kommer att tillämpa i det senare avsnittet om datorseende (Computer Vision) längre ner på denna sida.
Vill du ha en lite mer omfattande introduktion rekommenderar jag Introduction to TensorFlow 2.0: Easier for beginners, and more powerful for experts.
Intro to Machine Learning (ML Zero to Hero, part 1)
Prova själv den här koden i Hello World of Machine Learning: https://goo.gle/2Zp2ZF3
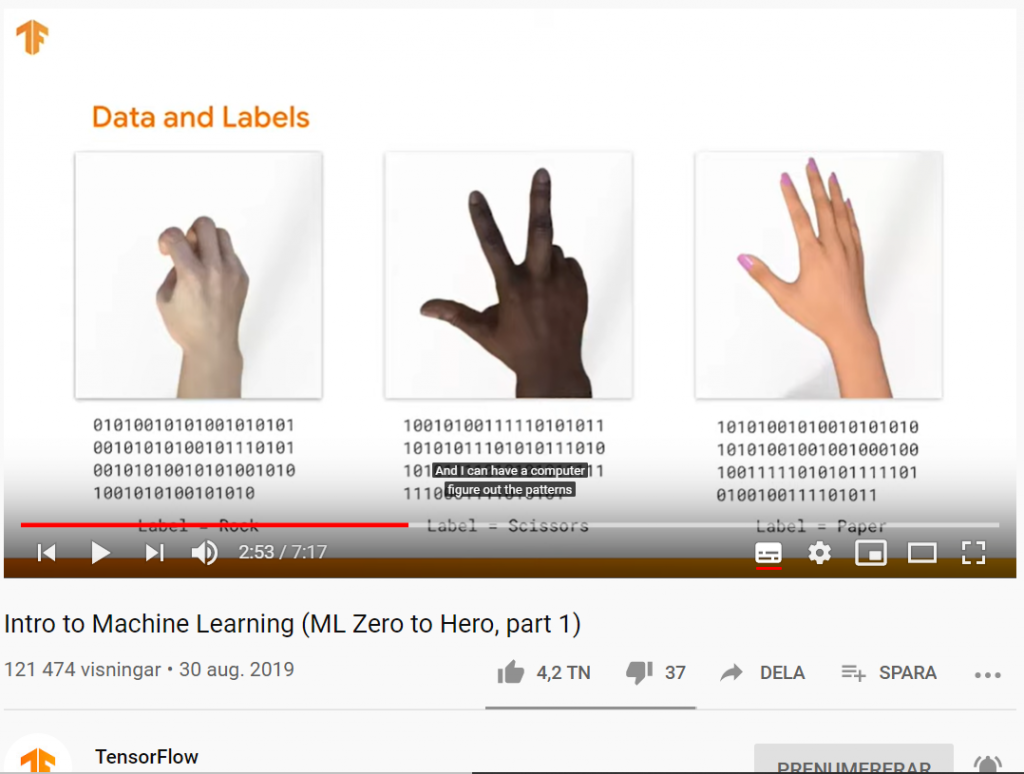
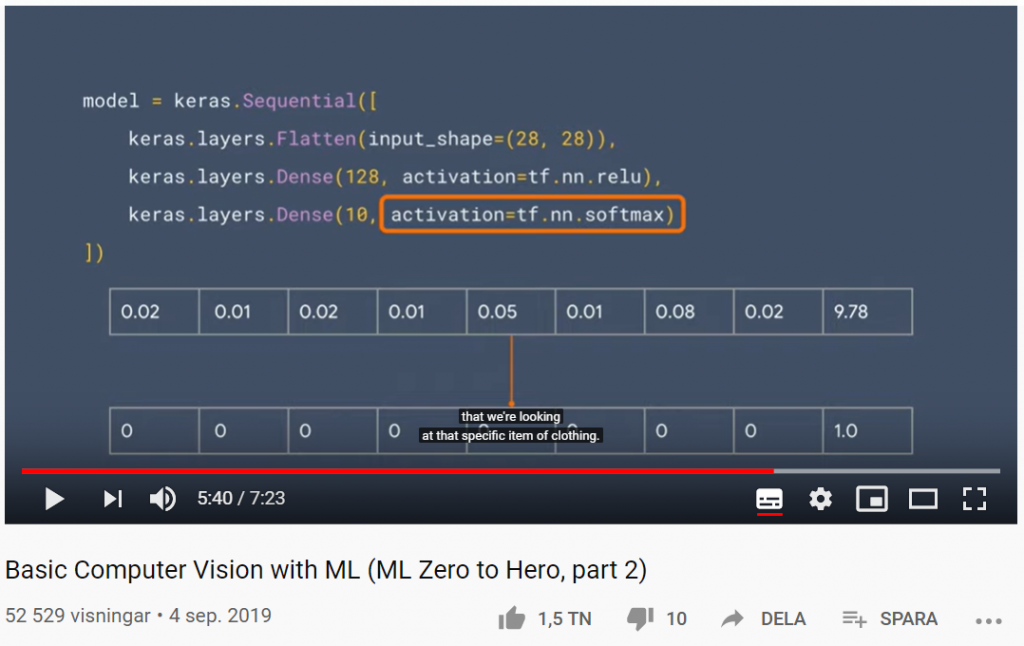
Basic Computer Vision with ML (ML Zero to Hero, part 2)
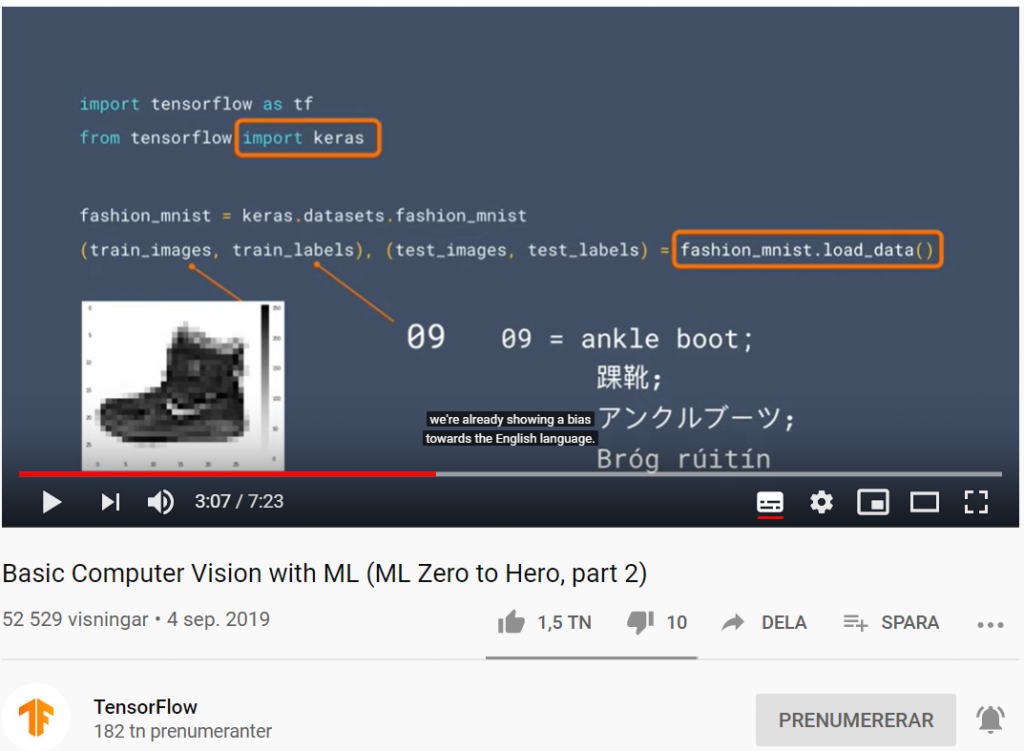
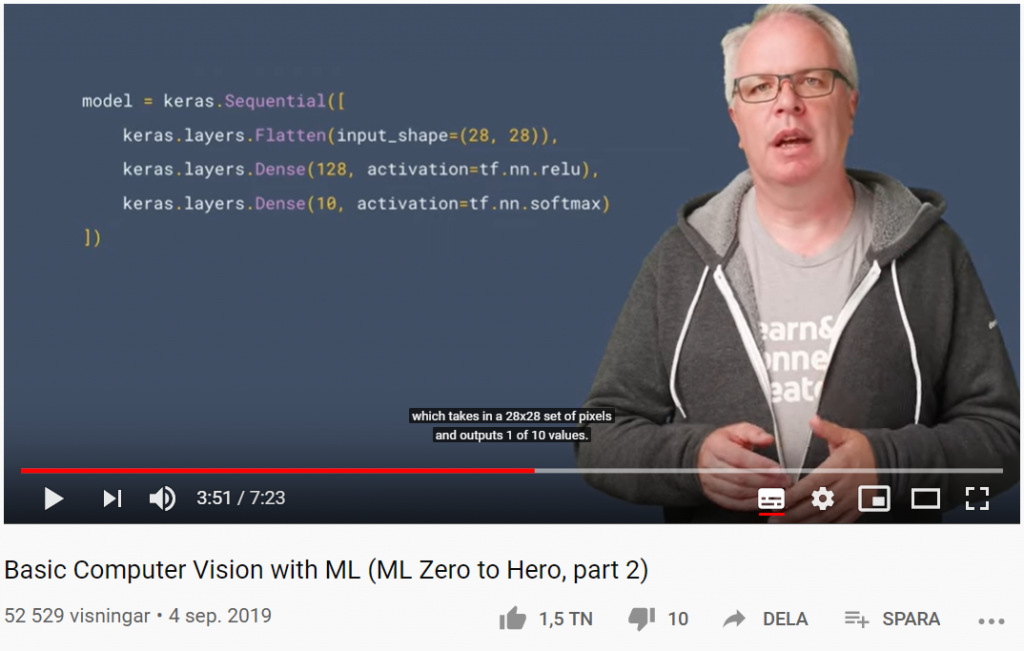
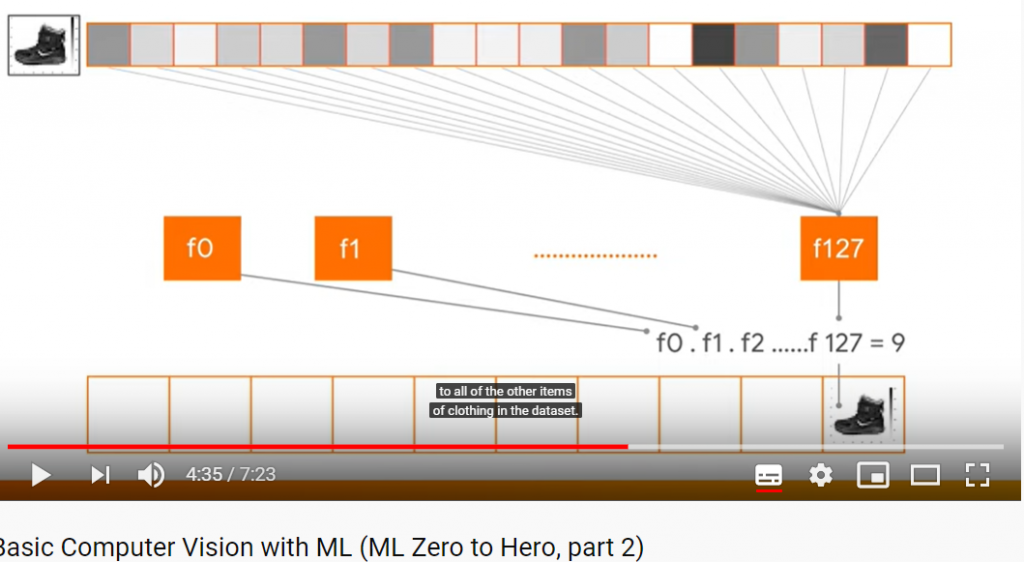
I del två av Machine Learning Zero to Hero går AI-evengalisten Laurence Moroney (lmoroney @) genom grundläggande datorseende (Computer Vision) med maskininlärning genom att lära en dator hur man ser och känner igen olika objekt (Object Recognition).
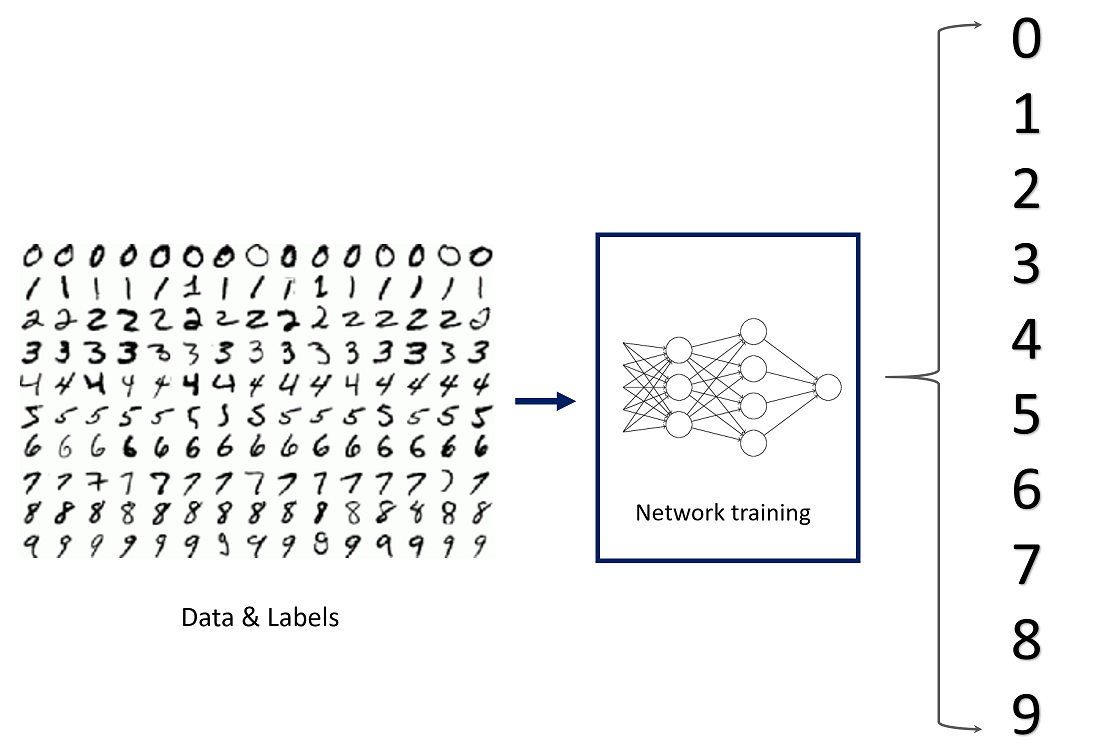
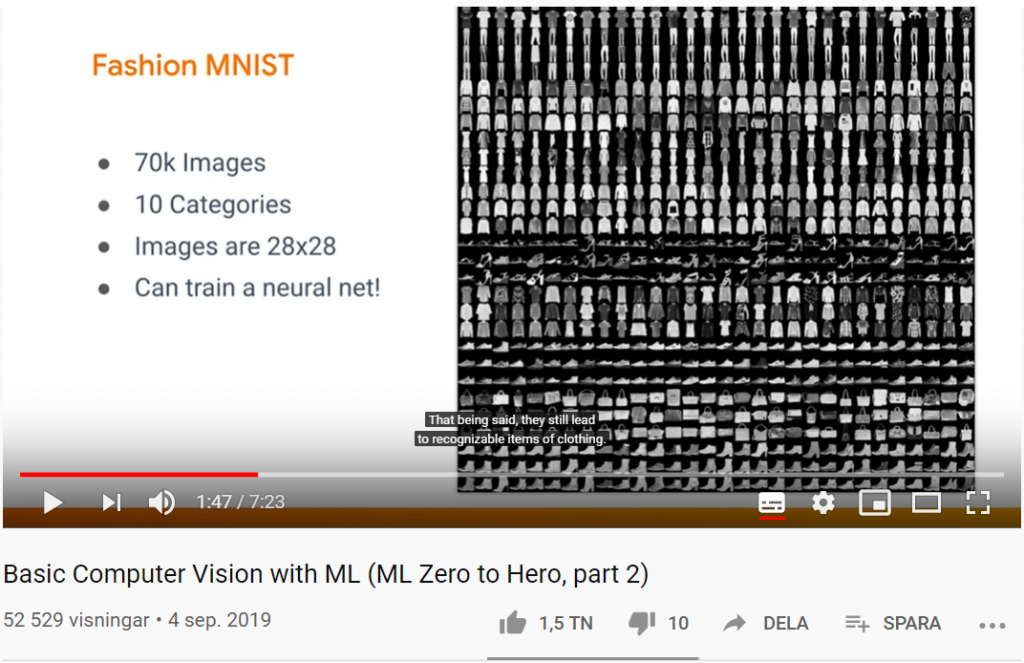
Fashion MNIST – ett dataset med bilder på kläder för benchmarking
Fashion-MNIST är ett forskningsprojekt av Kashif Rasul & Han Xiao i form av ett dataset av Zalandos artikelbilder. Det består av ett träningsset med 60 000 bildexempel och en testuppsättning med 10 000 exempel. Varje exempel är en 28 × 28 pixlar stor gråskalabild, associerad med en etikett från 10 klasser (klädkategorier).
Fashion-MNIST är avsett att fungera som en direkt drop-in-ersättning av det ursprungliga MNIST-datasättet för benchmarking av maskininlärningsalgoritmer.
Fashion MNIST dataset
Varför är detta av intresse för det vetenskapliga samfundet?
Det ursprungliga MNIST-datasättet innehåller många handskrivna siffror. Människor från AI / ML / Data Science community älskar detta dataset och använder det som ett riktmärke för att validera sina algoritmer. Faktum är att MNIST ofta är det första datasetet de provar på. ”Om det inte fungerar på MNIST, fungerar det inte alls”, sägs det. ”Tja, men om det fungerar på MNIST, kan det fortfarande misslyckas med andra.”
Fashion-MNIST är avsett att tjäna som en direkt drop-in ersättning för det ursprungliga MNIST-datasetet för att benchmarka maskininlärningsalgoritmer, eftersom det delar samma bildstorlek och strukturen för tränings- och testdelningar.
Varför ska man ersätta MNIST med Fashion MNIST? Här är några goda skäl:
- MNIST är för simpelt. Kolla denna side-by-side benchmark och “Most pairs of MNIST digits can be distinguished pretty well by just one pixel”.
- MNIST är överanvänt. kolla in “Ian Goodfellow wants people to move away from mnist.”
- MNIST kan inte representera moderna CV-uppgifter. Kolla in “François Cholle: Ideas on MNIST do not transfer to real CV.”
GitHub:
Find detailed information and the data set on GitHub

Här är ett exempel på datorseende som du kan testa själv: https://goo.gle/34cHkDk
Se mer om att koda TensorFlow → https://bit.ly/Coding-TensorFlow
Prenumerera på TensorFlow-kanalen → http://bit.ly/2ZtOqA3
Introducing convolutional neural networks (ML Zero to Hero, part 3)
I del tre av Machine Learning Zero to Hero diskuterar AI-evangelisten Laurence Moroney (lmoroney @) CNN-nätverk (Convolutional Neural Networks) och varför de är så kraftfulla i datorseende-scenarier. En ”convolution” är ett filter som passerar över en bild, bearbetar den och extraherar funktioner eller vissa kännetecken (features) i bilden. I den här videon ser du hur de fungerar genom att bearbeta en bild för att se om du kan hitta specifika kännetecken (features) i bilden.
Codelab: Introduktion till invändningar → http://bit.ly/2lGoC5f
Introducing convolutional neural networks (ML Zero to Hero, part 3)
Build an image classifier (ML Zero to Hero, part 4)
I del fyra av Machine Learning Zero to Hero diskuterar AI-evangelisten Laurence Moroney (lmoroney @) byggandet av en bildklassificerare för sten, sax och påse. I avsnitt ett visade vi ett scenario med sten, sax och påse, och diskuterade hur svårt det kan vara att skriva kod för att upptäcka och klassificera dessa. I de efterföljande avsnitten har vi lärt oss hur man bygger neurala nätverk för att upptäcka mönster av pixlarna i bilderna, att klassificera dem, och att upptäcka vissa kännetecken (features) med hjälp av bildklassificeringssystem med ett CNN-nätverk (Convolutional Neural Network). I det här avsnittet har vi lagt all information från de tre första delarna av serien i en.
Colab anteckningsbok: http://bit.ly/2lXXdw5
Rock, papper, saxdatasätt: http://bit.ly/2kbV92O
Build an image classifier (ML Zero to Hero, part 4)