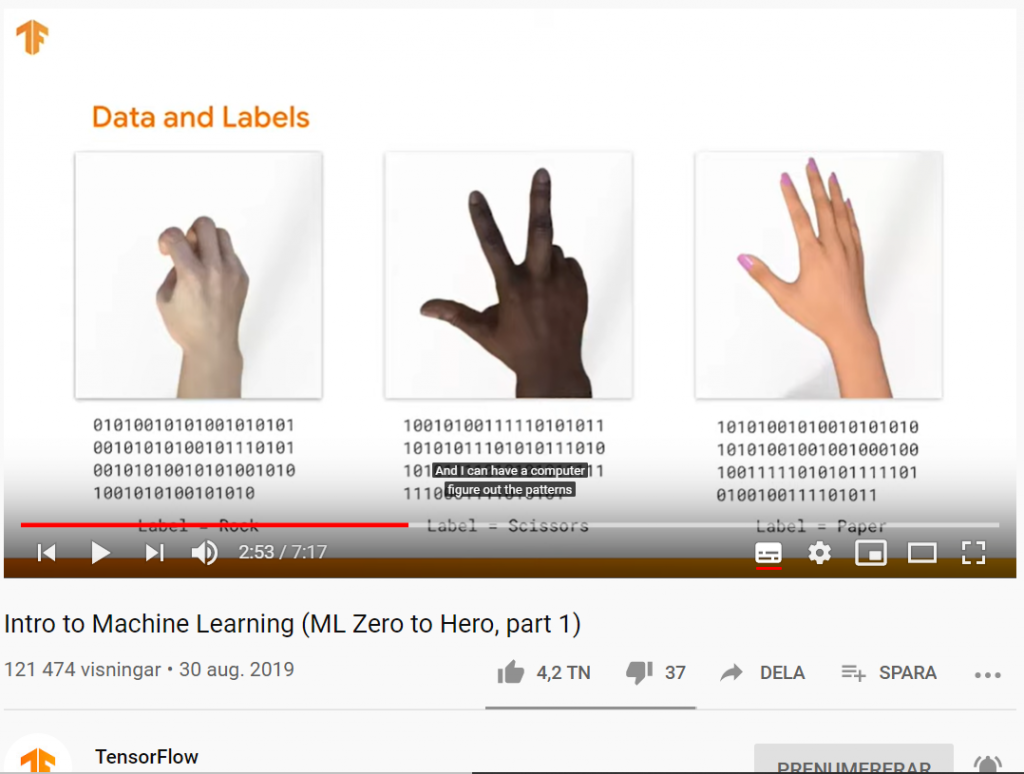
Här får du möjlighet att bestämma över Sveriges elproduktion. Utmaningen ligger i att ha tillräckligt med effekt när efterfrågan är som störst och att samtidigt hålla koll på miljökonsekvenserna. Du bygger – du bestämmer!
https://www.ekonomifakta.se/Fakta/Energi/Elsimulator/
Hur hanteras import/export?
Simulatorn räknar med att tillfälliga överskott exporteras som vid behov importeras senare.
Varje megawatt (MW) elproduktionskapacitet kan bara användas av ett land åt gången. Riktigt kalla dagar skapar ofta brist också i våra grannländer så varje land behöver tillräckligt med kapacitet för att klara effekttoppar.
Räknar ni med energibesparingar?
Vi räknar med dagens elbehov. I framtiden kan behovet av el både öka och minska.
Effektivare användning av elenergi ger ökad ekonomisk konkurrenskraft vilket leder till ekonomisk tillväxt som i sin tur historiskt sett alltid gett högre efterfrågan på el.
Räknar ni med lagring av el?
Vi har inte räknat med lagring av el i nuvarande versionen av Simulatorn.
Ett energilager skapar energiförluster på motsvarande 25 procent vilket gör att mer energi behöver produceras än om ett energilager inte används.
Räknar ni med smarta elnät?
Nej, men införande av smarta elnät ändrar grundläggande inte på våra beräkningar.
Solenergi har ingen tillgänglig effekt?
Tillgänglig effekt i simulatorn beräknas vid tidpunkten då efterfrågan på el är som störst. I Sverige inträffar detta kalla dagar mellan klockan 7-8 på förmiddagen. Eftersom solen inte har gått upp vid denna tidpunkt på vintern kan solpaneler inte producera någon ström då.
Så har vi räknat
Här kommer en beskrivning av hur vi har räknat ut effekt, energi och energiöverskott.
Effekt
Effekten är ett mått på energiproduktionskapaciteten hos en elproduktionsanläggning. Effekten kan delas upp i tre delar.
- Installerad effekt
- Medeleffekt
- Minsta tillgängliga effekt
Installerad effekt (Watt) är helt enkelt den högsta effekt som produktionsanläggningen kan producera. Medeleffekt beräknas genom att ta energiproduktionen (Wh) för en viss period (exempelvis ett år) och dela med antalet timmar för perioden (ett år är 365×24=8760 timmar).
Minsta tillgängliga effekt är den effekt som sannolikt finns tillgängligt vid tidpunkten för den högsta elförbrukningen. I Sverige inträffar den högsta elförbrukningen ungefär klockan 7 på morgonen under kalla vinterdagar.
För att beräkna tillgängligheten för olika kraftslag används Svenska Kraftnäts årliga balansrapport. Det högsta effektbehovet vid en normalvinter är 26 700 MW men vid en s.k. tioårsvinter kan effektbehovet uppgå till 27 700 MW. Tabellen nedan visar prognosen för installerad effekt vid årsskiftet 2019/20 (Svenska Kraftnät). Notera också att vi räknar bort den delen av gaskraften som ingår i störningsreserven (ca 1360 MW):
| Kraftslag | Installerad effekt | Tillgänglig effekt | Tillgänglighetsgrad |
| Vattenkraft | 16 318 | 13 400 | 82% |
| Kärnkraft | 7 710 | 6 939 | 90% |
| Solkraft | 745 | 0 | 0% |
| Vindkraft | 9 648 | 868 | 11% |
| Gasturbiner | 219 | 197 | 90% |
| Gasturbiner i störningsreserven | 1 358 | 0 | 0% |
| Olje-/kolkondens | 913 | 822 | 90% |
| Olje-/kolkondens otillgängligt för marknaden | 520 | 0 | 0% |
| Mottryck/kraftvärme | 4 622 | 3 536 | 77% |
| Mottryck/kraftvärme otillgängligt för marknaden | 450 | 0 | 0% |
| Summa | 40 503 | 25 762 | – |
Kolkraft och solenergi
I våra beräkningar gör vi bedömningen att kolkraft har motsvarande tillgänglighet som kärnkraft och gasturbiner nämligen 90%. För solenergi har vi valt att noll procent finns tillgängligt när effektbehovet vintertid är som störst. I Malmö går solen upp klockan 08:30 och går ner 15:37 vid midvintersolståndet den 21 december. Högst effektbehov uppstår vintertid före åtta och efter sexton då det alltså i hela Sverige fortfarande är mörkt.
- Kolkraft, 90% tillgänglig effekt.
- Solenergi, 0% tillgänglig effekt.
Svenska Kraftnät räknar med att det under vintern 2019/2020 finns 745 MW installerad solenergi i Sverige.
Beräkning av reglerkraft
När vi beräknar energi så startar vi först med hypotesen att alla anläggningar med låga produktionskostnader körs så mycket som möjligt. All produktion i icke-styrbara produktionsanläggningar som överstiger årsmedelproduktionen antas gå på export. Vind och sol i det nordiska elsystemet är ofta korrelerat så därför går det inte att importera just dessa kraftslag senare i obegränsad omfattning. Begränsningen till medeleffekten bedöms ändå vara generöst tilltaget.
Elbehov minus produktion utan reglerkraft minus export ger alltså behovet av reglerkraft.
Vattenkraften antas kunna användas fullt ut som reglerkraft även om det i genom vattendomar och andra fysiska begränsningar i praktiken inte är möjligt. När vattenkraften inte räcker till kan gasturbiner eller annan reglerkraft köras under begränsad tid. Reservanläggningar som vissa gasturbiner och oljekondenskraftverk beräknas köras i försumbar omfattning. Kärnkraft och kolkraft, när den finns, beräknas köras så många timmar som möjligt (ca 8 000 timmar per år).
Förenklingar
Simulatorn är tänkt att ge en känsla för begreppen installerad effekt, tillgänglig effekt och relationen till total energiproduktion. Vi tar inte hänsyn till följande saker
- Överföringsförluster
- Begränsningar i elnätet
- Begränsningar i vattenkraftens reglerförmåga
- Bara delvis tagit hänsyn till begränsningar för import/export
Dessa avgränsningar har gjorts för att göra simulatorn enkel att använda och ge största möjliga förståelse utan avkall på trovärdigheten i det större perspektivet.
Bränsle
Bränsleåtgång enligt följande tabell:
| Produktionstyp | Bränsle (gram/kWh) | Källa |
| Kärnkraft | 0.005 | Vattenfall |
| Kolkraft | 379 | IEA |
| Oljekondens | 331 | Novator |
| Bioeldad kraftvärme | 1000 | Novator |
| Naturgas | 187 | EPA |
Vindkraft, solenergi, och vattenkraft beräknas inte använda något bränsle.
Avfall
Kärnkraft genererar vid produktion avfall i form av använt kärnbränsle. Kolkraft och bioeldade kraftverk genererar fast avfall i form av aska.
| Produktionstyp | Avfall (gram/kWh) | Källa |
| Kärnkraft | 0.005 | Vattenfall |
| Kolkraft | 37 | Novator |
| Bioeldad kraftvärme | 15 | Novator |
Övriga produktionsslag antas ha lågt eller inget fast avfall.
Koldioxid CO2
Alla produktionsslag ger upphov till koldioxidutsläpp vid byggnation, bränsleutvinning, drift, rivning, etc. Utsläpp beräknas enligt livcykelmodellen. I första hand har vi använt Vattenfalls beräkningar och i andra hand valt andra källor. Koldioxidutsläpp i simulatorn beräknas enligt följande tabell
| Produktionstyp | Koldioxidutsläpp (gram/kWh) | Källa |
| Kärnkraft | 5 | Vattenfall |
| Kolkraft | 881 | IEA |
| Oljekondens | 993 | Novator |
| Bioeldad kraftvärme | 15 | Vattenfall |
| Naturgas | 515 | EPA |
| Vindkraft | 15 | Vattenfall |
| Vattenkraft | 9 | Vattenfall |
| Solenergi | 46 | Wikipedia |
Vattenkraft potential
Källa: SMHI Vattenkraft orörda älvar, Potential totalt (TWh) 35 Nyttjande tid (h) 4000 Fördelat på fyra älvar baserat på flöden ger följande potential per älv.
| Älv | Flöde (m3/s) | Procent | Energi (TWh) | Effekt (MW) |
| Torneälven | 388 | 35% | 12.4 | 5 662 |
| Kalixälven | 295 | 27% | 9.4 | 4 292 |
| Piteälven | 167 | 15% | 5.3 | 2 420 |
| Vindelälven | 249 | 23% | 7.9 | 3 607 |
| Summa | 1 099 | 100% | 35 | 15 981 |
Mer om elnät
Elnät används för att distribuera el från elproducenter till konsumenter. Kostnaden för elnäten beror i huvudsak på två faktorer, avstånd mellan produktion och konsumtion och hur effektivt elledningarna utnyttjas (kapacitetsfaktor).
Ett elnät med korta avstånd mellan produktion och konsumtion ger ett relativt billigare elnät jämfört med ett elnät med långa avstånd.
Långa avstånd ger också betydande överföringsförluster. En tumregel är att 6-10 procent av elen förloras per 1000 km i en 400 kilovolt högspänningsledning.
Enligt världsbanken är de genomsnittliga förluster för svenska elnätet 7 procent eller ungefär 10 TWh vilket är jämförbart med vindkraftens produktion 2013.
Ett elnät med korta avstånd och hög utnyttjandegrad per ledning är därför avgörande för att hålla kostnaderna och överföringsförlusterna så låga som möjligt.
För en vanlig elkund är elnätskostnaderna inte sällan högre än kostnaden för själva elen (elhandelskostnaden).